





I. Introduction▲
Lorsque nous construisons des applications, nous mettons en place des mécaniques plus ou moins complexes qui permettent l'implémentation de spécifications fonctionnelles. Ce petit jeu de construction a pour but ultime la satisfaction de la maitrise d'ouvrage (ou du client) à tous points de vue (respect des besoins exprimés, mais aussi réactivité dans les évolutions et corrections d'anomalies).
Durant la phase de développement, chaque développeur dispose de ses outils de débogage favoris pour tracer, analyser et améliorer les comportements applicatifs. Dès lors que l'application commence à vivre (déploiement en environnement d'intégration, puis en recette et enfin en production), les développeurs sont confrontés aux anomalies des testeurs et utilisateurs.
Le jeu de piste commence !
En effet, il n'est plus possible d'attacher un débogueur à l'application pour analyser et comprendre les manipulations qui provoquent les bogues.
Les développeurs doivent alors tenter de reconstituer les environnements incriminés (sources de données, configurations, etc.) afin d'identifier les anomalies.
Ce petit jeu, bien que très intéressant, demeure chronophage !
Il l'est d'autant plus que les développeurs ne disposent pas d'accès à l'environnement incriminé !
L'ajout de log systématique dans les projets permet, au pire, d'améliorer les temps de reproduction des anomalies, au mieux de comprendre directement quel est le composant, voire la ligne de code incriminée.
Cet article propose d'aborder deux frameworks de logs : le premier est natif au Framework.net, le second, plus complet, est nommé nLogs.
Ensuite, nous proposerons une solution de couplage faible entre consommateur et fournisseur de logs et enfin, nous conclurons par la présentation d'une mécanique de logs par une interception Unity ne nécessitant aucune ligne de code dans les fonctions appelées.
II. Sources▲
Une archive d'exemple est disponible ici : ArticleLog.zipSources de l'article. La solution contenue propose quatre projets :
- BDV.POC.ArticleLogs.ConsoSimpleLogsApp
Application console exposant la consommation des fournisseurs de logs par appel direct ; - BDV.POC.ArticleLogs.ConsoFactoryHomeMadeApp
Application console exposant la consommation des fournisseurs de logs via une fabrique abstraite ; - BDV.POC.ArticleLogs.ConsoUnityFactoryApp
Application console exposant l'utilisation des logs automatiquement via une interception Unity et via les instances Unity ; - BDV.POC.ArticleLogs.Loggers
Assembly contenant les fournisseurs de logs. Cet assembly est utilisé par les applications ConsoFactoryHomeMadeApp et ConsoUnityFactoryApp.
La solution a été réalisée à l'aide de Microsoft Visual Studio 2012.
III. TraceSource : la mécanique native Microsoft▲
Le Framework .net inclut une mécanique de logs nativement.
Cet outil, souvent méconnu, permet de mettre en place facilement, sans créer de dépendances sur des dll tierces, un log efficace et léger d'implémentation.
III-A. Principe de fonctionnement▲
Le code du développeur utilise une instance de la classe System.Diagnostics.TraceSource (Doc MSDNDocumentation TraceSource sur la MSDN) contenue dans l'assembly System (System.dll).
Cette classe existe depuis le Framework 2.0.
L'instance de cette classe se voit injecter des messages à tracer en fonction d'un niveau de trace (de type TraceLevel Doc MSDNEnumeration TraceLevel sur la MSDN).
Le flux de fonctionnement observé est le suivant :
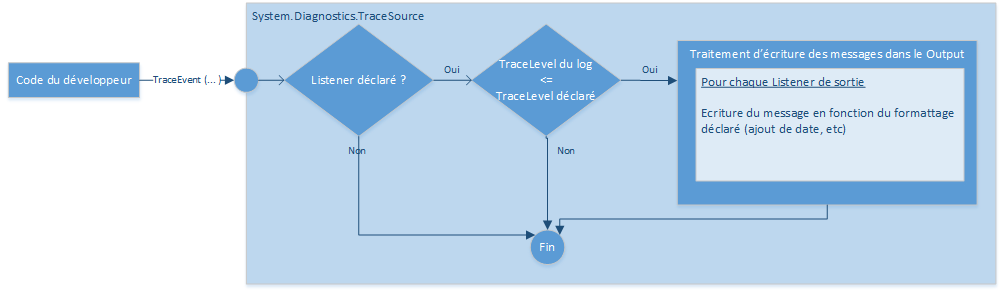
Le flux décrit ci-dessus simplifie la réalité volontairement.
Je vous invite à consulter le code de la classe à l'aide d'un outil tel que ReflectorReflector (payant) ou IL SpyIL Spy (gratuit).
III-B. Implémentation▲
La déclaration de l'instance TraceSource est triviale :
TraceSource _monTraceur = new TraceSource("[Identifiant-Du-Traceur]");La déclaration nécessite de préciser (a minima) l'identifiant du traceur.
Cet identifiant sera utilisé ultérieurement dans le fichier de configuration pour préciser les comportements attendus par le traceur.
L'identifiant doit être une chaine de caractères sans espace.
N'utiliser que les caractères alphanumériques non accentués ([a-z] [A-Z] [0-9]) pour l'identifiant du traceur.
L'utilisation de l'instance TraceSource ne présente aucune difficulté particulière :
this._monTraceur.TraceEvent(TraceEventType.Information, 1);
this._monTraceur.TraceEvent(TraceEventType.Warning, 2, "Mon message à tracer !");Les utilisations faites ci-dessus tracent une information et un avertissement. D'autres niveaux existent.
L'utilisation nécessite de préciser a minima (premier appel) :
- le niveau (Information, Warning, Error, Critical, etc.) ;
- l'id de l'évènement tracé
Le principe d'ID d'évènement est le suivant :
la valeur identifie l'évènement ou la fonctionnalité de façon unique dans le projet (voire l'application),
le développeur est libre d'utiliser n'importe quelle valeur entre 0 et xxx,
lorsqu'utilisé, il est intéressant de garder une table de correspondance entre l'id et sa description dans une documentation de projet.
Il peut ne pas être utilisé (initialisation à une valeur unique lors de l'appel de TraceEvent).
Le second appel correspond à l'utilisation la plus fréquente. Les paramètres de base (ci-dessus) se voient complétés par le message tracé.
III-C. Paramétrage▲
Le paramétrage se réalise dans le fichier de configuration de l'application.
Le paramétrage manipule les concepts suivants :
- source
Une « source » est une structure permettant de paramétrer une instance de TraceSource.
Le lien se réalise par l'intermédiaire du nom de la source qui doit correspondre au nom indiqué lors de l'instanciation de l'objet TraceSource.
Si le nom précisé ne correspond à aucune source paramétrée, aucun comportement ne sera exécuté (pas d'exception retournée ni de log).
Le paramétrage disponible permet le filtrage de contenu en fonction du niveau souhaité. D'autres filtrages sont possibles (cf. documentation).
La source se voit déclarer de 0 à n listeners.
Ces déclarations peuvent pointer vers un listener partagé ou spécifique. - listener
Un « listener » représente une interface de sortie de la trace.
Au cours de l'exemple, nous avons utilisé un TextWriterTraceListener qui écrit dans un fichier texte.
D'autres Listeners existent (Console, Event logs, XML, etc.), il demeure possible de créer vos propres customs listeners (implémentation de la classe abstraite System.Diagnostics.TraceListener).
<configuration>
...
<system.diagnostics>
<trace autoflush="true" /> <!-- Permet de ne pas devoir flusher à chaque écriture -->
<sources>
<source name="App" switchValue="Warning">
<listeners>
<clear />
<!-- Utilisation du traceur partagé nommé FileListener -->
<add name="FileListener" />
</listeners>
</source>
<source name="UserFunctionality" switchValue="All">
<listeners>
<clear />
<!-- Utilisation du traceur partagé nommé FileListener -->
<add name="FileListener" />
</listeners>
</source>
<source name="LeTraceurDeBase" switchValue="All">
<listeners>
<clear />
<!-- Déclaration d'un listener spécifique pour LeTraceurDeBase -->
<add name="TraceurBaseFileListener"
type="System.Diagnostics.TextWriterTraceListener"
initializeData=".\BaseTraceLog.txt" traceOutputOptions="DateTime" />
</listeners>
</source>
</sources>
<!-Déclaration des Listeners partagés -->
<sharedListeners>
<add name="FileListener"
type="System.Diagnostics.TextWriterTraceListener"
initializeData=".\TraceLog.txt" traceOutputOptions="DateTime" />
</sharedListeners>
</system.diagnostics>
...
</configuration>IV. Utilisation d'un Framework de logs : nLog▲
Il existe de nombreux frameworks de logs pour le Framework Microsoft.net. Ils ont tous en commun un ensemble de principes (sortie, niveau de trace, formatage, etc.).
Le choix nLog se motive par la maturité du projet, le nombre de fonctionnalités natives, sa légèreté, et son extensibilité.
Nos équipes utilisent ce framework de logs depuis plusieurs années sans avoir rencontré d'erreurs majeures.
Nous avons également testé Log4net qui s'avère un bon outil.
Log4net dispose d'un excellent tuto sur developpez : https://lutecefalco.developpez.com/tutoriels/dotnet/log4net/introduction/http://lutecefalco.developpez.com/tutoriels/dotnet/log4net/introduction/.
Le projet est hébergé à cet endroit http://nlog-project.org/http://nlog-project.org/.
IV-A. Implémentation▲
L'implémentation différente de TraceSource demeure triviale.
La récupération d'une instance de logs se réalise comme suit :
var loggerInstance1 = NLog.LogManager.GetLogger("LoggerName");Le principe d'utilisation demeure similaire à celui de tracesource, même si les méthodes sont différentes.
En effet, le choix du niveau de log se réalise par appel de la méthode de log correspondante.
loggerInstance1.Warn("Log with trace source started.");
loggerInstance1.Error("User enter 'Q' > Exit signal launched.");Ci-dessus, nous logguons en mode Warning, et Error. D'autres niveaux existent.
Le logger nécessite de préciser le message à logguer a minima.
D'autres surcharges existent (cf. documentation nlog).
IV-B. Paramétrage▲
Le paramétrage basique est très simple. Il consiste à ajouter une déclaration section de configuration et la configuration qui lui est liée.
Les sections de configuration (appelée aussi configSection) sont des structures permettant la sérialisation/désérialisation des blocs XML contenus dans les fichiers de configuration des applications .net.
Tous les blocs utilisés dans nos fichiers de configuration ont une configSection déclarée.
Cette déclaration se situe dans le fichier machine.config pour toutes les configSection de base.
NLogs nécessite une déclaration particulière, car le framework n'est pas nativement connu par le Framework.net.
La déclaration des configSection se réalise en début de fichier.
Déclaration de la section de configuration :
<configuration>
<configSections>
<!-- Déclaration du type pour la désérialisation des infos de configuration de nLogs contenues dans ce fichier de config -->
<section name="nlog" type="NLog.Config.ConfigSectionHandler, NLog" />
</configSections>
...
<configuration>Il convient ensuite de compléter le fichier de configuration par la déclaration de la configuration propre à nLogs :
Lors de la déclaration de la section de configuration, nous avons précisé « nlog » dans l'attribut « name ».
Cette valeur indique le nom de l'élément XML correspondant à la configuration dans le fichier XML.
<!-- DEBUT - Configuration nLogs - DEBUT -->
<nlog
xmlns="http://www.nlog-project.org/schemas/NLog.xsd"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" autoReload="true">
<targets>
<target name="file" xsi:type="File"
layout="${longdate} ${logger} ${message}"
fileName="[${shortdate}][${machinename}]Trace.txt" />
</targets>
<rules>
<logger name="*" minlevel="Trace" writeTo="file" />
</rules>
</nlog>
<!-- FIN - Configuration nLogs - FIN -->La configuration ci-dessus est basique, elle a comme résultat un fichier de log unique contenant toutes les sorties de logs.
Il est possible de séparer les logs dans des sorties différentes en fonction du niveau, ou d'autres critères tels que le nom du logger, le contenu du message, etc. Je vous invite à tester toutes les possibilités offertes dans un POC (Proof Of Concept).
Toute la documentation est accessible ici : http://nlog-project.org/http://nlog-project.org/.
La configuration nLogs permet de préciser le format de sortie des lignes de logs (attribut layout ci-dessus).
V. TraceSource vs nLogs en cinq points▲
| TraceSource | nLogs |
| Ne dispose pas d'une mécanique de fichiers tournants. | Mécanique de fichiers tournants native selon un ensemble de critères. Exemple : si le pattern du nom de fichier inclut la date en format aaaammjj, il y aura un fichier par jour. |
| Les sorties de type fichier sont en accès exclusif. Toute opération de suppression/renommage/modification du fichier est impossible tant que l'application s'exécute. |
Les fichiers ne sont pas verrouillés, dès lors les opérations de suppression/renommage/modification de fichiers sont possibles à chaud. |
| Formatage des messages dans la sortie réalisé dans le code. | Le fichier de configuration permet de définir un pattern de logging dans la sortie, sans recompilation. Il est possible d'agrémenter les mots-clés disponibles pour les patterns de formatage (déclaration de variables de log $NomVariable alimentée par le code et dont l'utilisation demeure paramétrable via le pattern défini dans le fichier de conf). |
| Sorties disponibles nativement : - fichier ; - trace ASP.net ; - event logs Windows. |
Sélection de quelques sorties disponibles parmi les 39 disponibles nativement : - fichiers plats ; - fichiers XML ; - webService ; - message Queue ; - database ; - mail ; - WMI. Ces mécaniques de sorties peuvent se voir agrémentées de comportements annexes (Load Balancing, asynchrone, routage de sortie en fonction de critères, etc.). |
| Uniquement Framework.net depuis la version 2.0 (pas de Compact Framework) et Mono. | Multiplateforme : - Framework.net - Compact Framework.net - Mono (Windows/Linux, et donc Mac). |
VI. Rendre le code découplé de la solution de logs▲
Jusqu'ici, les exemples proposés couplent fortement le code client qui consomme le service de logs à la solution technique choisie.
En effet, les déclarations et appels des instances responsables du log se réalisent par appels directs !
Le remplacement d'une solution de logs par une autre est donc impossible sans devoir recoder les lignes où elle est utilisée.
Ce couplage fort entre consommateur et fournisseur de services est handicapant à bien des points de vue :
- quelle solution adopter si un client désire adopter une autre solution de logs (afin d'uniformiser les API au sein d'un parc applicatif) ? ;
- quelle stratégie mener si une anomalie bloquante affecte le framework de logs utilisé (ce qui peut arriver, tout framework extérieur au projet présente un risque) ? ;
- comment résoudre une demande client qu'un framework tiers ne remplit pas ? ;
- quelle architecture proposer lors du développement d'une API à fournir à un partenaire, en permettant la visualisation du log, sans imposer la solution de log ?
La réponse à ces problématiques est simple : adoptons le principe du code « ouvert/fermé ». À savoir que tout code doit être ouvert pour l'extension, mais fermé aux modifications.
En d'autres termes, nous externalisons ce qui change, ou ce qui présente un risque de changement. Le couplage entre le code appelant et le code appelé se réalise alors sur la base d'interfaces (contrats). Ce couplage sera alors qualifié de faible.
La conséquence est la suivante : le changement d'un protagoniste (appelant ou appelé) n'influence pas l'autre, et ne nécessite donc, pas sa réouverture pour modification (pas de test nécessaire donc).
Je vous encourage vivement à acquérir le livre Tête la Première dans les Design Patterns disponible auprès d'Immatériel (référence du livrehttp://librairie.immateriel.fr/fr/ebook/9782815000031/design-patterns-tete-la-premiere). Cet ouvrage vous permettra d'acquérir les principes de base des Designs Patterns, et ce de façon ludique.
VI-A. Principe de fonctionnement▲
Dans l'exemple qui nous concerne, nous optons pour l'adoption d'une « fabrique abstraite » sur un fournisseur de services de logs (ILogManager).
ILogManager permettra à l'appelant d'obtenir des instances responsables de produire les logs.

Le diagramme supérieur montre le principe de la fabrique abstraite ; l'inférieure décrit son application pour le cas qui nous concerne.
Notre code applicatif est alors couplé à des contrats d'implémentation ILogManager et ILogger et non aux instances du framework de logs choisi.
ILogManager constitue le contrat de fabrique des instances responsables de logger. Il propose donc une seule méthode permettant de récupérer des instances de ILogger.
ILogger expose les méthodes d'un composant capable de logger : WriteError(…), WriteInfo(…), etc.

Le changement de framework de logs se limite alors à coder deux nouvelles classes : une instance ILogManager, et une ILogger !
Le diagramme ci-dessus indique trois implémentations de fournisseur de logs :
- LogManagerForNLog et LoggerForNLog
Implémentation exploitant nLog ; - LogManagerForTraceSource et LoggerForTraceSource
Implémentation exploitant TraceSource ; - LogManagerForDisable et LoggerForDisable
Implémentation ne disposant d'aucun comportement. Ce stratagème est utilisé afin de permettre au code appelant la logique de log de ne pas devoir vérifier la nullité des instances de logs. L'appel ne générant aucun log.
Par défaut, une instance doit être retournée. Si aucune solution de log ne doit être indiquée, le type retourné est une instance LogManagerForDisable.
Ce faible couplage a un coût faible, si adopté dès le début du projet.
Son retour sur investissement (ROI) est important.
VI-B. Implémentation▲
L'implémentation peut être faite via un Framework IOC de type Unity, ou par l'implémentation du pattern de fabrique abstraite à la main. L'exemple montre le second cas.
La déclaration d'un ILogManager et la récupération d'une instance ILogger demeure somme toute aussi simple que l'adoption par appel direct (moyennant la précision du nom du logger) :
ILogManager _logManager = LoggerFactory.GetLogManager();
var myLogger = _logManager.GetLogger("App");Dans l'exemple de code, nous n'utilisons pas le Framework IOC (type Unity) pour retourner les instances de fabriques. Nous disposons d'un point d'entrée statique nommé LoggerFactory qui se charge de retourner les instances de fabrique de loggers.
Exemple d'utilisation de « ILogger » :
myLogger.WriteWarning("Application is starting...");
myLogger.WriteWarning("Program", "Main", "SetCompatibleTextRenderingDefault");Le premier appel loggue un message simple, le second précise le nom de la classe, la méthode et le message à logguer.
Le contrat de ILogger propose un log sur quatre niveaux (Error > Warning > Information > Verbose) connu par la majorité des frameworks de logs. Pour chaque niveau, le contrat propose deux méthodes de logs en fonction des besoins des développeurs :
- non détaillé : seul le message est à préciser ;
- détaillé : les informations suivantes sont précisées, et formatées lors du log
o nom de la classe,
o méthode de la classe,
o message.
Complément d'information à destination des utilisateurs avertis des Designs Patterns : une fabrique simple aurait pu faire l'affaire pour retourner des instances de ILogger (et donc, se passer de ILogManager). Dans de nombreux cas, nous avons le besoin d'interagir avec un gestionnaire de la couche de logs pour un ensemble de tâches.
Exemple : modification du niveau de logs de façon applicative, ajout de filtres de sortie dynamiquement, etc. D'où la fabrique abstraite.
Ce mode d'implémentation (à la main) permet de découpler le code appelant de l'implémentation, mais laisse un couplage plus fort entre assembly (l'assembly de l'appelant référence l'assembly de la fabrique abstraite). L'utilisation de Unity permet de disposer du couplage faible absolu.
VI-C. Paramétrage▲
Le paramétrage n'est pas lié à l'implémentation d'une solution de couplage faible, mais bien à la solution de logs implémentée. Dès lors, aucune précision n'est nécessaire en plus de ce qui existe déjà pour les Frameworks de logs
VII. Quelles informations logger▲
J'espère qu'à ce stade de l'article, vous êtes convaincu de l'intérêt du log.
Il nous reste deux aspects à évoquer :
- quoi (le contenu) ;
- quand (localisation dans les sources).
La réponse à ces questions correspond à la tentative de résolution de l'énigme suivante :
« De quoi ai-je besoin, sur un environnement de production, comme information tracée pour évaluer rapidement ? » :
- le composant logiciel (voire la ligne de code en cause) incriminé ;
- le contexte d'exécution qui provoque l'anomalie.
Idéalement, nous devons donc disposer d'un log :
- lors de l'entrée et sortie dans une fonction principale, ou une séquence de traitement important ;
- avant l'exécution d'opérations particulières ;
- dans le catch d'exception pour logguer le détail de l'exception ;
- il convient (si possible) de traiter également les exceptions non gérées (en WPF il s'agit de l'évènement Application UnhandledException).
Le contenu tracé doit refléter clairement la classe, la méthode et idéalement les paramètres entrant, voire le retour de fonction (si cela est possible).
La conséquence de ce genre de log est la quantité énorme de contenu généré (ceux qui connaissent les ULS SharePoint voient de quoi je parle).
Heureusement, nous pouvons jouer sur les niveaux de trace pour éviter la quantité énorme de log lors des phases d'exploitation normales.
Le mode Trace (sous nlog) ou Verbose (sous TraceSource) correspond au niveau de log développeur.
VIII. Automatisation du log par l'interception Unity▲
Le diktat du log présente un inconvénient non négligeable : il nécessite un effort de la part de l'équipe de développement.
Cet effort produit un nombre plus ou moins important de lignes de code supplémentaires à celles liées aux algorithmes initiaux.
Enfin, cet effort présente (souvent) un caractère jugé inintéressant par les équipes (donc, risque de messages mal formés, ou bogues).
Il existe une solution technique qui peut permettre de répondre à ces trois inconvénients, tout en respectant la bonne pratique de log.
Cette solution n'est pas « native », elle découle d'un développement que j'ai réalisé et que je vous encourage à utiliser (tant que vous précisez dans vos sources l'origine du code source en question).
Si vous souhaitez le modifier afin de l'adapter à vos contextes applicatifs : libre à vous !
L'unique contrainte à l'utilisation est la suivante : afin de permettre l'interception Unity de log, il est impératif que vous conceviez vos couches métier sur base du principe Ouvert/Fermé et de fabriques abstraites mises en place sous Unity (version 3 pour l'exemple).
L'exemple fourni contient les classes responsables de cette automatisation.
VIII-A. Principe de fonctionnement▲
Mais avant de les nommer, attardons-nous sur les principes utilisés par le dernier exemple fourni.
Au début de cet article, nous évoquions le modèle de fabrique abstraite. Si nous appliquons ce principe aux classes de services couplées au fournisseur d'IOC Unity, le diagramme de couches sera le suivant :
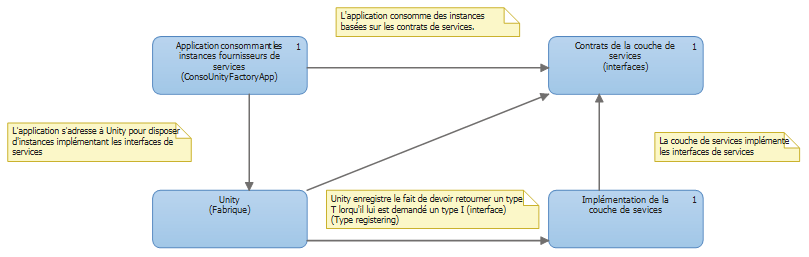
L'application consommatrice de la couche de services est liée aux interfaces de celle-ci (et non aux classes d'implémentation).
Elle s'adresse à Unity pour lui fabriquer les instances implémentant les interfaces de services.
Ce principe de base de fonctionnement apporte un gain important en termes de couplage faible.
Unity propose un principe d'Interception. Ce principe dit que, en lieu et place du type déclaré à l'interface, Unity va retourner un proxy qui permet d'intercepter tous les appels effectués et de les rerouter vers des instances implémentant IInterceptionBehavior sous la forme d'une chaîne de responsabilités (encore un Design Pattern) pour laquelle le dernier maillon appelé est l'appel réel sur le type attendu (voir schéma ci-dessous).
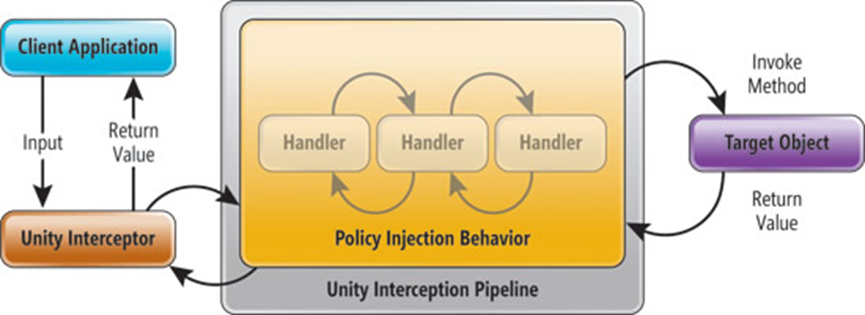
En d'autres termes, lorsque l'application demande à Unity une instance de service, ce dernier ne retourne pas directement le type d'implémentation attendu, mais bien l'instance d'un proxy (Unity Interceptor) qui intercepte tous les appels effectués sur les méthodes ou propriétés.
Une fois l'interception faite, les appels sont effectués sous la forme d'une chaine de responsabilité (Unity Interception Pipeline) où chaque maillon est une instance d'IInterceptorBehavior. Lorsque toutes les instances ont consommé/analysé l'appel (paramètres, etc.) le dernier maillon de la chaine est l'appel réel sur la méthode d'implémentation de la classe de services (Target Object).
Le retour s'effectue de la même manière, en sens inverse.
Tout ceci se réalise de façon transparente pour l'application qui consomme le service. En effet, cette dernière ne traite que sur des types d'interface ! Dès lors, que l'instance retournée soit d'un type A ou B, cela lui importe peu.
Dans notre cas de figure (le log automatique) la classe qui implémente l'interception est de type LoggerInterceptionBehavior. Elle est contenue dans BDV.POC.ArticleLog.Loggers.UnityExtensions.
Le comportement est complété par la mécanique de log (pour laquelle l'intercepteur est lui-même couplé faiblement aux instances d'ILogManager) et une classe d'extension sur le log permettant de retourner sous la forme d'une chaîne de caractères la description d'un objet. Cette dernière mécanique est contenue dans la classe LoggerExtender située dans BDV.POC.ArticleLog.Loggers.Contracts.
Nous vous conseillons de déboguer tous les appels entre l'application console et la méthode de service cible en pas à pas afin de bien visualiser le comportement. N'hésitez pas à vous servir de l'espion afin de visualiser les types retournés par les containers Unity.
L'exemple se sert du Framework Unity pour réaliser les IOC et interceptions.
D'autres frameworks présentent également une mécanique d'interception et d'IOC : SpringSpring, Castle Dynamic ProxyCastle Dynamic Proxy.
Il est également possible d'automatiser le log via le principe d'AOP. Le framework PostsharpPostsharpexpose ce principe. Le tutoriel suivant présente le principe : Redécouvrez les custom attributs avec PostSharpRedécouvrez les custom attributs avec PostSharp.
Néanmoins, l'AOP présente comme inconvénient de devoir modifier le code source pour ajouter les attributs correspondant au tracing.
VIII-B. Implémentation▲
Nous vous invitons à placer un point d'arrêt dans la méthode DoSomething afin de tracer le comportement.
L'implémentation n'est pas triviale : l'utilisation de Unity nécessite de prendre en mains la mécanique !
Il convient de
- paramétrer Unity ;
- charger une configuration Unity ;
- récupérer des instances pour les appels clients.
VIII-B-1. Chargement de la configuration Unity▲
Le chargement d'une configuration sous la forme XML se réalise comme suit :
// Instanciation d'un conteneur
var container = new UnityContainer();
// Récupération de la configuration Unity depuis le fichier de configuration de l'application
var section = (UnityConfigurationSection)ConfigurationManager.GetSection("unity");
// Chargement du conteneur, avec la configuration de conteneur portant le nom "WithInterception"
Microsoft.Practices.Unity.Configuration.UnityContainerExtensions.LoadConfiguration(container, section, "WithInterception");La première ligne instancie un objet UnityContainer.
La seconde ligne récupère la configuration contenue dans le bloc XML du fichier de configuration par le biais d'une section de configuration (type héritant de ConfigSection).
La troisième ligne charge dans le conteneur la configuration de conteneur nommée « WithInterception ».
L'exemple indique également que le conteneur est un singleton (design pattern). Ceci est motivé par l'inutilité de recharger à la demande la configuration unity, une fois monté en mémoire, il convient de l'utiliser !
VIII-B-2. Récupération des instances▲
Afin de garder un couplage faible entre consommateur de service, implémentation fonctionnelle du service et solution d'IOC, nous optons pour un projet intermédiaire nommé UnityLoader. Ce choix n'est pas indispensable à l'utilisation de Unity ; ce choix permet d'encapsuler la complexité Unity derrière une façade (design pattern) et ainsi, de faciliter le travail des développeurs.
Vu de l'application consommatrice, la récupération consiste donc à appeler la façade statique et de demander la résolution de type :
ServicesProvider.GetInstanceOf<BDV.POC.ArticleLog.Services.IExempleServiceMetier>();La récupération réelle de l'instance auprès du conteneur Unity se réalise dans le code de la façade sous la forme suivante :
GetCurrentUnityContainer().Resolve<T>();Dans l'exemple de code, GetCurrentUnityContainer est une méthode privée qui instancie (si nécessaire) et retourne l'instance Singleton (design pattern) de type UnityContainer responsable de la résolution de type.
L'appel de la méthode d'extension Resolve<T>(); résout la demande d'instance. Cette méthode d'extension permet de simplifier l'appel réel Resolve(Type t, string name, params ResolverOverride[] resolver).
VIII-C. Paramétrage▲
Le paramétrage peut être effectué en code (c#, vb.net, etc.) ou en XML. Nous ne traiterons que la configuration XML (utilisée dans l'exemple)
Le paramétrage consiste à :
- indiquer au Framework Unity quels sont les types qui seront demandés par les consommateurs, et quels sont les types à instancier en face ;
- préciser les paramètres des constructeurs des types à instancier ;
- préciser les interceptions éventuelles.
Nous ne détaillerons pas toutes les possibilités de Unity (cet article n'a pas cette vocation), il précise uniquement les concepts utilisés dans les exemples.
VIII-C-1. Configuration▲
Il convient d'abord de préciser le type de section de configuration attendu lors de la désérialisation du bloc XML.
<configSections>
…
<section name="unity" type="Microsoft.Practices.Unity.Configuration.UnityConfigurationSection, Microsoft.Practices.Unity.Configuration, Version=3.0.1208.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35"/>
…
</configSections>La section ci-dessus indique que le bloc connu dans le fichier sous l'élément « unity » (par la balise name), est à désérialiser dans le type indiqué par la balise type, UnityConfigurationSection.
La configuration en elle-même est contenue dans l'élément « unity » tel que ci-dessous
<unity>
<sectionExtension type="Microsoft.Practices.Unity.InterceptionExtension.Configuration.InterceptionConfigurationExtension, Microsoft.Practices.Unity.Interception.Configuration" />
<container name="Main">
<extension type="Interception" />
<types>
<type
type="BDV.POC.ArticleLog.Loggers.ILogManager, BDV.POC.ArticleLog.Loggers.Contracts"
mapTo="BDV.POC.ArticleLog.Loggers.NLogProvider.LogManagerForNLog, BDV.POC.ArticleLog.Loggers" >
</type>
<type
type="BDV.POC.ArticleLog.Services.IExempleServiceMetier, BDV.POC.ArticleLog.Services.Contracts"
mapTo="BDV.POC.ArticleLog.Services.ExempleServiceMetier, BDV.POC.ArticleLog.Services">
<interceptor type="InterfaceInterceptor"/>
<interceptionBehavior
type="BDV.POC.ArticleLog.Loggers.LoggerInterceptionBehavior, BDV.POC.ArticleLog.Loggers.UnityExtensions" />
</type>
</types>
</container>
</unity>Dans le bloc ci-dessus, nous pouvons lire les éléments suivants :
déclaration d'un conteneur nommé « Main » ;
- déclaration d'une extension (sorte de plugin) de type « Interception » ;
- déclaration d'un ensemble de types abstraits (interfaces) avec leur implémentation à retourner
o ILogManader
La configuration indique qu'il faut retourner une instance de LogManagerForNLog lorsqu'il est demandé un ILogManager,
o IExempleServiceMetier
La configuration indique qu'il faut retourner une instance de ExempleServiceMetier lorsqu'il est demandé un IExempleServiceMetier.
Il est précisé que tous les appels sur IExempleServiceMetier (propriété ou méthode) doivent être interceptés et redirigés vers une instance de LoggerInterceptionBehavior Nous attirons votre attention sur le fait que l'instanciation de ExempleServiceMetier nécessite de préciser une instance de ILogManager. Étant donné que la configuration précise le type retourné pour les ILogManager, la résolution est implicite. Dans le cas contraire, il aurait fallu indiquer les paramètres du constructeur par le biais de la balise « constructor » et la précision de balises « param ».
IX. Conclusion▲
L'adoption d'une solution de log dans le code développé est aujourd'hui incontournable. Le choix du framework utilisé (TraceSource, nLog, autres) dépend du besoin de log.
Pour un besoin « basique », la classe TraceSource suffit.
Pour des besoins plus élaborés, nLogs s'avère une solution pérenne. Il est important de préciser que d'autres frameworks existent et méritent également d'être adoptés.
Dans tous les cas, l'utilisation directe des instances responsables des logs sans adopter le principe de couplage faible par l'intermédiaire des fabriques abstraites présente en apparence une simplicité d'utilisation.
Mais le couplage important entre le code développé et le fournisseur de logs est un inconvénient majeur.
En d'autres termes : si le fournisseur de logs n'apporte plus satisfaction, il sera extrêmement couteux à remplacer.
Si on ajoute le principe « Ouvert/Fermé » dès le début du projet, le couplage faible apportera une sécurité supplémentaire quant à la qualité du composant logiciel fourni.
X. Pour en savoir plus▲
- Documentation TraceSource (MSDN)Documentation TraceSource dans la MSDN.
- Documentation nLogs (site officiel)http://nlog-project.org/.
- Article MSDN Magazine interception http://msdn.microsoft.com/fr-fr/magazine/gg598927.aspxArticle MSDN Magasine interception http://msdn.microsoft.com/fr-fr/magazine/gg598927.aspx.
- Unity sur le codeplexUnity sur le codeplex .
- SpringSpring.
- Castle Dynamic ProxyCastle Dynamic Proxy.
- Postsharp.Postsharp
XI. Remerciements▲
Je tiens à remercier tout particulièrement Thomas Levesque, Kevin Perriat, Claude Leloup, David Veyssiere, Nicolas Guerrazzi, Eric Sembille et Aymeric Mortemousque pour leurs relectures et remarques constructives.